Java對象在內(nèi)存中的結(jié)構(gòu)與數(shù)據(jù)處理、存儲支持服務(wù)探析
在Java應(yīng)用程序的運行過程中,對象作為數(shù)據(jù)與操作的載體,其內(nèi)存結(jié)構(gòu)的理解對于性能優(yōu)化、問題排查及系統(tǒng)設(shè)計至關(guān)重要。現(xiàn)代數(shù)據(jù)處理與存儲支持服務(wù)為這些對象的高效管理提供了堅實后盾。本文將深入探討Java對象在內(nèi)存中的布局,并分析其與后端數(shù)據(jù)處理、存儲服務(wù)的關(guān)聯(lián)。
一、 Java對象在內(nèi)存中的結(jié)構(gòu)
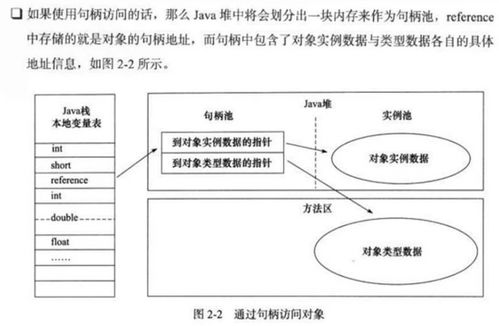
Java對象在堆內(nèi)存(Heap)中的存儲結(jié)構(gòu)通常包含三個主要部分:對象頭(Header)、實例數(shù)據(jù)(Instance Data)和對齊填充(Padding)。
- 對象頭(Header):存儲對象的元數(shù)據(jù)。
- Mark Word:用于存儲對象自身的運行時數(shù)據(jù),如哈希碼、GC分代年齡、鎖狀態(tài)標(biāo)志、線程持有的鎖、偏向線程ID等。這部分?jǐn)?shù)據(jù)在32位和64位虛擬機(jī)上長度不同,并且會根據(jù)對象狀態(tài)復(fù)用存儲空間。
- 類型指針(Klass Pointer):指向?qū)ο笏鶎兕愒獢?shù)據(jù)(Klass)的指針,虛擬機(jī)通過此指針確定對象是哪個類的實例。在開啟指針壓縮(-XX:+UseCompressedOops,默認(rèn)開啟)的64位JVM中,此指針通常為4字節(jié)。
- 數(shù)組長度:如果對象是數(shù)組,對象頭中還會包含一塊用于記錄數(shù)組長度的數(shù)據(jù)。
- 實例數(shù)據(jù)(Instance Data):存儲對象中各個類型的字段內(nèi)容,包括從父類繼承下來的字段。字段的存儲順序會受到虛擬機(jī)分配策略參數(shù)(-XX:FieldsAllocationStyle)和字段在Java源碼中定義順序的影響。基本類型數(shù)據(jù)會直接存儲,而引用類型則存儲指向另一塊內(nèi)存區(qū)域的指針。
- 對齊填充(Padding):并非必然存在。HotSpot VM要求對象起始地址必須是8字節(jié)的整數(shù)倍,因此當(dāng)對象頭與實例數(shù)據(jù)的總大小不是8的倍數(shù)時,就需要通過對齊填充來補(bǔ)全。這主要是為了內(nèi)存尋址的效率。
內(nèi)存布局示例:一個簡單的User對象(包含int id, String name字段)在內(nèi)存中,會先有對象頭,然后是id的4字節(jié)數(shù)據(jù),接著是指向String對象的引用(通常4或8字節(jié)),最后可能有填充字節(jié)。其實際占用的內(nèi)存空間可通過工具(如JOL庫)精確分析。
二、 數(shù)據(jù)處理與存儲支持服務(wù)對Java對象管理的意義
Java對象在內(nèi)存中創(chuàng)建和消亡,但其承載的數(shù)據(jù)往往需要持久化、共享或進(jìn)行復(fù)雜計算。這就需要后端的數(shù)據(jù)處理與存儲服務(wù)提供支持。
- 序列化與反序列化:這是內(nèi)存對象與存儲/傳輸格式轉(zhuǎn)換的橋梁。當(dāng)需要將對象存入數(shù)據(jù)庫(如MySQL)、緩存(如Redis)、消息隊列(如Kafka)或進(jìn)行網(wǎng)絡(luò)傳輸(RPC調(diào)用)時,對象必須被序列化為字節(jié)流(如使用JDK序列化、JSON、Protobuf等)。反之,從這些服務(wù)讀取數(shù)據(jù)時,則需要反序列化回內(nèi)存中的Java對象。理解對象內(nèi)存結(jié)構(gòu)有助于選擇或設(shè)計高效的序列化方案。
- ORM框架與內(nèi)存映射:對象關(guān)系映射框架(如MyBatis, Hibernate)的核心工作之一,就是將數(shù)據(jù)庫表中的行數(shù)據(jù),高效地組裝成內(nèi)存中的Java對象(及其對象圖)。這個過程涉及字段映射、懶加載、緩存等機(jī)制,其效率與對象的內(nèi)存結(jié)構(gòu)緊密相關(guān)。優(yōu)化實體類設(shè)計(如避免過深的繼承層次、謹(jǐn)慎使用大對象)能提升ORM性能。
- 緩存服務(wù):分布式緩存(如Redis, Memcached)常被用來存儲熱點數(shù)據(jù)對象,以減少數(shù)據(jù)庫壓力和訪問延遲。緩存中的對象通常是序列化后的形態(tài)。對象的設(shè)計(如大小、復(fù)雜度)直接影響序列化/反序列化的開銷和網(wǎng)絡(luò)傳輸效率,進(jìn)而影響緩存性能。有時,會將對象拆分為多個更細(xì)粒度的緩存鍵來優(yōu)化。
- 大數(shù)據(jù)處理與列式存儲:在處理海量數(shù)據(jù)時(如使用Spark、Flink),數(shù)據(jù)常以內(nèi)部數(shù)據(jù)結(jié)構(gòu)(如Row,本質(zhì)也是對象)在內(nèi)存中流轉(zhuǎn)。列式存儲格式(如Parquet, ORC)在持久化時,改變了數(shù)據(jù)的組織方式,使其更利于壓縮和批量分析。了解對象內(nèi)存布局有助于理解這些框架為何能進(jìn)行高效的序列化(如Spark的Tungsten項目)和內(nèi)存管理。
- 堆外內(nèi)存與網(wǎng)絡(luò)傳輸:為了規(guī)避GC停頓、實現(xiàn)零拷貝或與本地庫交互,高級應(yīng)用會使用堆外內(nèi)存(DirectByteBuffer)。Netty等網(wǎng)絡(luò)框架大量使用堆外內(nèi)存來存儲和傳輸數(shù)據(jù)。數(shù)據(jù)從Java對象寫入堆外緩沖區(qū),或反之讀取,都涉及高效的內(nèi)存拷貝與布局轉(zhuǎn)換,這與對象的字段排列息息相關(guān)。
三、 實踐啟示與優(yōu)化方向
- 對象設(shè)計優(yōu)化:盡量使對象小巧、扁平,避免不必要的字段,謹(jǐn)慎使用大對象(如大數(shù)組),以降低內(nèi)存占用和序列化開銷。
- 序列化選型:根據(jù)場景選擇高效序列化協(xié)議(如Protobuf、Kryo、Hessian),它們能生成更緊湊的字節(jié)流,比JDK原生序列化性能更優(yōu)。
- 緩存策略:考慮緩存對象的粒度與形態(tài),對于復(fù)雜對象,可緩存其部分字段或計算后的結(jié)果。
- 監(jiān)控與剖析:利用JVM工具(如MAT, VisualVM)分析堆內(nèi)存快照,識別內(nèi)存中重復(fù)、冗余或過大的對象結(jié)構(gòu),結(jié)合業(yè)務(wù)邏輯進(jìn)行優(yōu)化。
###
Java對象的內(nèi)存結(jié)構(gòu)是JVM層面的微觀細(xì)節(jié),而數(shù)據(jù)處理與存儲支持服務(wù)是應(yīng)用架構(gòu)中的宏觀支撐。深刻理解前者,能讓我們更好地駕馭后者,從而在設(shè)計高效、可擴(kuò)展的數(shù)據(jù)驅(qū)動型應(yīng)用時做出更明智的決策。從對象字段的排列,到跨進(jìn)程的數(shù)據(jù)流動,再到磁盤上的字節(jié)布局,這條數(shù)據(jù)鏈路上的每一環(huán)都值得我們深入探究與優(yōu)化。
如若轉(zhuǎn)載,請注明出處:http://www.k1us3.cn/product/67.html
更新時間:2026-01-22 02:58:26